Nie jestem do końca pewien, czy to pytanie jest odpowiednie dla Stack Overflow, ale mimo to udzielę podstawowej odpowiedzi. Chociaż jest to bardzo skomplikowane pytanie, ponieważ w zależności od tego, jak głęboko chciałbyś odpowiedzieć, mógłbym napisać całą książkę o architekturze komputera, aby to zrobić.
Tak więc, aby to było proste, po prostu dam ci to: To wszystko jest kwestią kontekstu. Najpierw zajmijmy się tekstem:
Po otwarciu, powiedzmy, edytora tekstu, domyślnym założeniem jest, że dane, które mają być wyświetlane, mają charakter tekstowy. Tekst do wyświetlenia to niektóre bajty w pamięci (ewentualnie skopiowane z niektórych bajtów na dysku). Nie ma magicznego wewnętrznego kontekstu z punktu widzenia pamięci, że te bajty są tekstem. Zamiast tego, źródło edytora tekstu zawiera kilka komend wskazujących na te bajty i mówiących "te bajty reprezentują 300 znaków tekstu" na przykład. Następnie jest złożona sekwencja kroków obejmujących kod biblioteki aż po sprzęt, który obsługuje mapowanie tych bajtów zgodnie z kodowaniem takim jak ASCII (istnieje wiele innych sposobów kodowania tekstu) dla znaków, znajdowanie tych znaków w czcionce, pisanie tej czcionki do ekran, itp.
Chodzi o to, że nie mają interpretować te bajty jako tekst. Po prostu dlatego, że tak robi edytor tekstu. Możesz hipotetycznie otworzyć go w programie graficznym i nakazać interpretację tych samych 300 bajtów co tablica 10x10 (lub obraz) wartości RGB.
Jeśli chodzi o kolory, obowiązuje ta sama logika. To tylko bajty w pamięci. Ale kiedy kod, który rysuje coś na ekranie, zdecydował, jakie piksele chce zapisać w jakich kolorach, przesunie te bajty za pomocą odwzorowania pamięci na kartę graficzną, która następnie przetłumaczy je na polecenia wysyłane do monitora (nadal w jakimś binarnym formacie reprezentującym piksele i kolory, choć rzeczywistość jest o wiele bardziej skomplikowana), a sam monitor zawiera oprogramowanie, które następnie obsługuje szczegóły mapowania tych kolorów do fizycznych pikseli. Liczby reprezentujące same kolory zostaną w pewnym momencie przeliczone na konkretny prąd dla każdego kanału R/G/B w celu zwiększenia lub zmniejszenia jego intensywności.
To wszystko, na co mam czas, ale to dopiero początek.
Aktualizacja: Dla zilustrowania mojego punktu, wziąłem tekst Flatland z here. To zaledwie 216624 bajty tekstu ASCII (zinterpretowane jako takie przez przeglądarkę internetową w oparciu o kontekst: pomaga rozszerzenie txt, ale serwer WWW udostępnia również nagłówek typu MIME informujący przeglądarkę, że powinien on być interpretowany jako zwykły tekst. może również analizować bajty, aby określić, że ich wzorzec wygląda jak zwykły tekst (i że nie ma przytłaczającej liczby bajtów, które nie reprezentują znaków ASCII).I dołączone kilka spacji na końcu tekstu, dzięki czemu jego długość wynosi 217.083, który jest 269 * 269 * 3, a następnie wykreślono go jako 269 x 269 RGB obrazu:
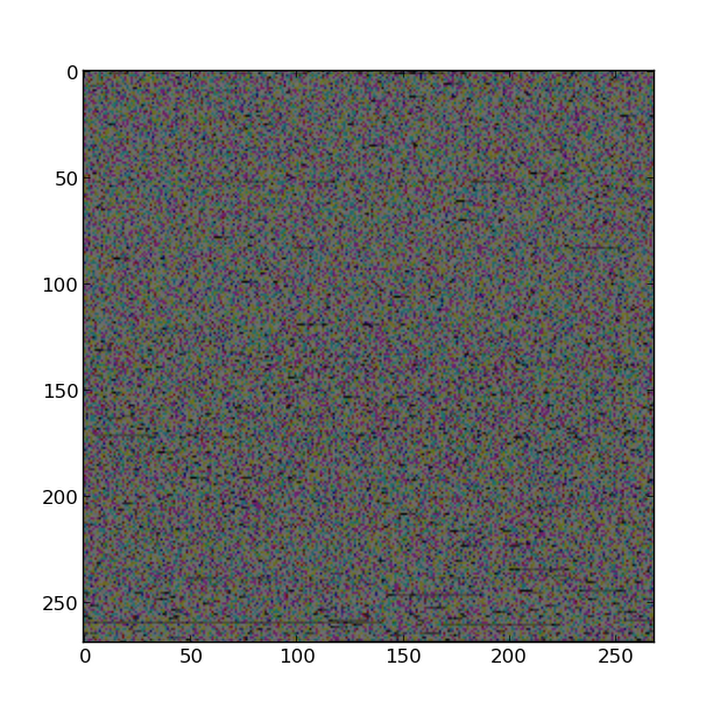
nieszczególnie interesujące wyglądające . Ale chodzi o to, że po prostu wziąłem te same dokładne bajty i powiedziałem programowi: "okej, teraz są wartości RGB". Nie oznacza to, że przeglądanie zwykłych bajtów jako obrazów nie może być użyteczne. Na przykład może to być przydatny sposób wizualizacji algorytmu szyfrowania. This pokazuje obraz, który został zaszyfrowany przy użyciu dość niezabezpieczonego algorytmu - nadal można uzyskać bardzo dobry obraz wzorców bajtów w oryginalnym pliku niezaszyfrowanym. Gdyby był tekstem, a nie obrazem, nie byłoby to inne, ponieważ tekst w określonym języku, takim jak angielski, również ma znane wzorce statystyczne. Dobry algorytm szyfrowania sprawi, że zaszyfrowany obraz będzie bardziej przypominał losowy szum.
{kind=link}
Oprócz mojej odpowiedzi poniżej, jeśli chcesz wiedzieć, jak działają komputery zaczynając od najniższego poziomu, proponuję lekturę: Computer Organization and Design (autorzy Patterson, Hennessy). Jeśli to czytasz (lub czytasz inny równoważny materiał), zobaczysz nawet, jak działa procesor, a uzyskasz lepsze zrozumienie maszyny i jej wielu poziomów. – Numbers
Tak, zgadzam się. Myślę, że książka na temat architektury/organizacji Comp zaspokoiłaby wiele moich ostatnich ciekawostek. Dobry telefon, dzięki. – ThisBetterWork
Propozycja +1 do @Numbers. Zamierzałem zasugerować tę samą książkę. – Iguananaut