Podejście brute force byłoby spróbować dodanie listy do każdego dostępnego indeksu za pomocą przeszukiwanie w głąb.
Tak więc, zaczynając od "a", istnieją dwa miejsca, w których można dodać nową literę. Z przodu lub z tyłu "a", reprezentowane przez kropki poniżej.
.a.
Jeśli dodać 'T', istnieją obecnie trzy pozycje.
.a.t.
Można spróbować dodać wszystkie 26 liter do każdej dostępnej pozycji. Słownik w tym przypadku może być prostym hashtable. Jeśli dodasz "z" w środku, otrzymasz "azt", który nie będzie w hashtable, więc nie będziesz kontynuował tej ścieżki w wyszukiwaniu.
Edytuj: Wykres Nicka Johnsona sprawił, że byłem ciekawy, jak mógłby wyglądać wykres wszystkich maksymalnych ścieżek. Jest to duży (1,6 MB) obraz tutaj:
http://www.michaelfogleman.com/static/images/word_graph.png
Edit: Oto implementacja Pythona. Metoda brute-force działa w rozsądnym czasie (kilka sekund, w zależności od litery początkowej).
import heapq
letters = 'abcdefghijklmnopqrstuvwxyz'
def search(words, word, path):
path.append(word)
yield tuple(path)
for i in xrange(len(word)+1):
before, after = word[:i], word[i:]
for c in letters:
new_word = '%s%s%s' % (before, c, after)
if new_word in words:
for new_path in search(words, new_word, path):
yield new_path
path.pop()
def load(path):
result = set()
with open(path, 'r') as f:
for line in f:
word = line.lower().strip()
result.add(word)
return result
def find_top(paths, n):
gen = ((len(x), x) for x in paths)
return heapq.nlargest(n, gen)
if __name__ == '__main__':
words = load('TWL06.txt')
gen = search(words, 'b', [])
top = find_top(gen, 10)
for path in top:
print path
Oczywiście w odpowiedzi będzie wiele powiązań. Spowoduje to wydrukowanie najlepszych wyników N, mierzonych długością ostatniego słowa.
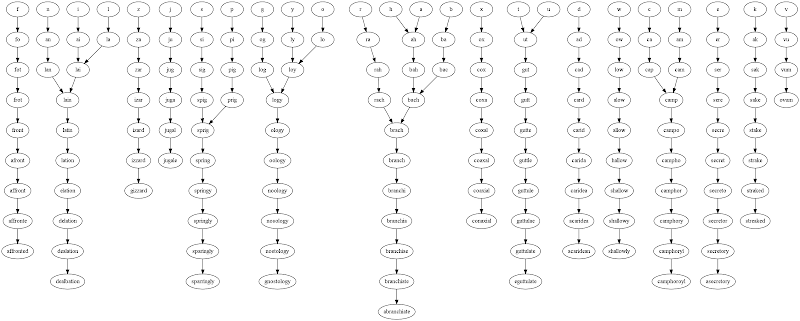
Wyjście dla litery początkowej "a", przy użyciu słownika Scrabble TWL06.
(10, ('a', 'ta', 'tap', 'tape', 'taped', 'tamped', 'stamped', 'stampede', 'stampedes', 'stampeders'))
(10, ('a', 'ta', 'tap', 'tape', 'taped', 'tamped', 'stamped', 'stampede', 'stampeder', 'stampeders'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'strangle', 'strangles', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'strangle', 'strangler', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranges', 'strangles', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranges', 'strangers', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranges', 'strangers', 'estrangers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranges', 'estranges', 'estrangers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranger', 'strangler', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranger', 'strangers', 'stranglers'))
Oto wyniki dla każdej litery początkowej. Oczywiście wyjątek jest taki, że pojedyncza litera początkowa nie musi znajdować się w słowniku. Tylko jakieś 2-literowe słowo, które można z niego utworzyć.
(10, ('a', 'ta', 'tap', 'tape', 'taped', 'tamped', 'stamped', 'stampede', 'stampedes', 'stampeders'))
(9, ('b', 'bo', 'bos', 'bods', 'bodes', 'bodies', 'boodies', 'bloodies', 'bloodiest'))
(1, ('c',))
(10, ('d', 'od', 'cod', 'coed', 'coped', 'comped', 'compted', 'competed', 'completed', 'complected'))
(10, ('e', 're', 'rue', 'ruse', 'ruses', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(9, ('f', 'fe', 'foe', 'fore', 'forge', 'forges', 'forgoes', 'forgoers', 'foregoers'))
(10, ('g', 'ag', 'tag', 'tang', 'stang', 'strang', 'strange', 'strangle', 'strangles', 'stranglers'))
(9, ('h', 'sh', 'she', 'shes', 'ashes', 'sashes', 'slashes', 'splashes', 'splashers'))
(11, ('i', 'pi', 'pin', 'ping', 'oping', 'coping', 'comping', 'compting', 'competing', 'completing', 'complecting'))
(7, ('j', 'jo', 'joy', 'joky', 'jokey', 'jockey', 'jockeys'))
(9, ('k', 'ki', 'kin', 'akin', 'takin', 'takins', 'takings', 'talkings', 'stalkings'))
(10, ('l', 'la', 'las', 'lass', 'lassi', 'lassis', 'lassies', 'glassies', 'glassines', 'glassiness'))
(10, ('m', 'ma', 'mas', 'mars', 'maras', 'madras', 'madrasa', 'madrassa', 'madrassas', 'madrassahs'))
(11, ('n', 'in', 'pin', 'ping', 'oping', 'coping', 'comping', 'compting', 'competing', 'completing', 'complecting'))
(10, ('o', 'os', 'ose', 'rose', 'rouse', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(11, ('p', 'pi', 'pin', 'ping', 'oping', 'coping', 'comping', 'compting', 'competing', 'completing', 'complecting'))
(3, ('q', 'qi', 'qis'))
(10, ('r', 're', 'rue', 'ruse', 'ruses', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(10, ('s', 'us', 'use', 'uses', 'ruses', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(10, ('t', 'ti', 'tin', 'ting', 'sting', 'sating', 'stating', 'estating', 'restating', 'restarting'))
(10, ('u', 'us', 'use', 'uses', 'ruses', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(1, ('v',))
(9, ('w', 'we', 'wae', 'wake', 'wakes', 'wackes', 'wackest', 'wackiest', 'whackiest'))
(8, ('x', 'ax', 'max', 'maxi', 'maxim', 'maxima', 'maximal', 'maximals'))
(8, ('y', 'ye', 'tye', 'stye', 'styed', 'stayed', 'strayed', 'estrayed'))
(8, ('z', 'za', 'zoa', 'zona', 'zonae', 'zonate', 'zonated', 'ozonated'))
{kind=link}
Interesujący problem. Co próbowałeś do tej pory i gdzie utknąłeś? –
Zdefiniuj "słownik słów". Czy to jest tablica hash, trie lub co? Jeśli jest to triest, działa proste wyszukiwanie DF. Czy jest to drzewo sufiksu, jak sugerują twoje tagi? – IVlad
Brzmi jak zadanie domowe, źle określone. –