10
Analizuję demontaż następującego (bardzo prostego) programu C w GDB na X86_64.Adresowanie zmiennych stosu
int main()
{
int a = 5;
int b = a + 6;
return 0;
}
Rozumiem, że w X86_64 stos rośnie. To jest górna część stosu ma niższy adres niż dół stosu. Assembler z powyższego programu jest następujący:
Dump of assembler code for function main:
0x0000000000400474 <+0>: push %rbp
0x0000000000400475 <+1>: mov %rsp,%rbp
0x0000000000400478 <+4>: movl $0x5,-0x8(%rbp)
0x000000000040047f <+11>: mov -0x8(%rbp),%eax
0x0000000000400482 <+14>: add $0x6,%eax
0x0000000000400485 <+17>: mov %eax,-0x4(%rbp)
0x0000000000400488 <+20>: mov $0x0,%eax
0x000000000040048d <+25>: leaveq
0x000000000040048e <+26>: retq
End of assembler dump.
Rozumiem, że:
- Mamy przesunąć wskaźnik bazowy na stosie.
- Następnie kopiujemy wartość wskaźnika stosu do wskaźnika bazowego.
- Następnie kopiujemy wartość 5 na adres
-0x8(%rbp). Ponieważ w int wynosi 4 bajty, nie powinno to być na następnym adresie w stosie, który jest-0x4(%rbp)zamiast ?. - Następnie kopiujemy wartość ze zmiennej
ado%eax, dodajemy 6, a następnie kopiujemy wartość do adresu pod-0x4(%rbp).
Korzystanie z tej grafiki na odniesienie:
http://eli.thegreenplace.net/images/2011/08/x64_frame_nonleaf.png
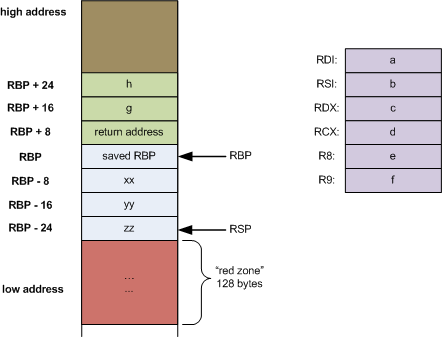{kind=link}
wygląda stosu ma następującą zawartość:
|--------------|
| rbp | <-- %rbp
| 11 | <-- -0x4(%rbp)
| 5 | <-- -0x8(%rbp)
gdy spodziewałem się następująco:
|--------------|
| rbp | <-- %rbp
| 5 | <-- -0x4(%rbp)
| 11 | <-- -0x8(%rbp)
whi ch wydaje się być w przypadku 7-understanding-c-by-learning-assembly gdzie oni pokazują montaż:
(gdb) disassemble
Dump of assembler code for function main:
0x0000000100000f50 <main+0>: push %rbp
0x0000000100000f51 <main+1>: mov %rsp,%rbp
0x0000000100000f54 <main+4>: mov $0x0,%eax
0x0000000100000f59 <main+9>: movl $0x0,-0x4(%rbp)
0x0000000100000f60 <main+16>: movl $0x5,-0x8(%rbp)
0x0000000100000f67 <main+23>: mov -0x8(%rbp),%ecx
0x0000000100000f6a <main+26>: add $0x6,%ecx
0x0000000100000f70 <main+32>: mov %ecx,-0xc(%rbp)
0x0000000100000f73 <main+35>: pop %rbp
0x0000000100000f74 <main+36>: retq
End of assembler dump.
Dlaczego wartość b jest oddany do wyższej adresu pamięci w stosie niż a gdy a wyraźnie zadeklarowane i zainicjowana w pierwszej kolejności?
Kompilator może dowolnie zaalokować zmienne czasu trwania na stosie, jeśli tak się czuje. Tylko najbardziej naiwni kompilatorzy przejdą przez kod i na każdym wyjściu deklaracji i zasięgu zmienią wskaźnik stosu, a różne kompilatory i ich wersje mogą wypluć inny kod. Sam standard C nie ma nic do powiedzenia na temat względnych adresów dwóch automatycznych zmiennych. –